

이 글은 유데미 강의 ‘Docker & Kubernetes : 실전 가이드’의 쿠폰을 제공받아 수강하고 작성된 글입니다.
개요
개발을 해오면서 도커라는 도구를 아주 유용하게 쓰고 있다.
도커는 공식 문서와 참고 자료들이 아주 잘 정리되어 있고, 이들을 따라하는 것만으로도 쉽게 컨테이너를 생성해 운영할 수 있다.
하지만 그만큼 도커의 목적, 동작 원리 등에 대한 이해도를 갖추는 것에 소홀해지기 쉬운 것 같다고 느껴, 좋은 강의를 제공받은 김에 본 글에서는 도커의 동작 원리와 도커가 등장한 목적에 대해 살펴보고자 한다.
도커
도커란?
도커란, 컨테이너를 생성하고 관리하기 위한 도구다.
도커를 접해봤거나 사용해본 사람이라면 위와 같은 도커의 정의와 컨테이너란 단어가 익숙할 것이다. 하지만 여기서 의미하는 컨테이너가 무엇인지에 대한 깊은 고민은 해 본 적이 없었다.
컨테이너란?
위의 컨테이너는 도커라는 툴에 종속된 개념이 아니다. (즉, ‘도커 컨테이너’ 자체를 의미하는 것이 아님)
컨테이너란, 코드를 실행하기 위해 필요한 모든 종속성/도구를 패키징할 수 있는 표준화된 기술이다.
즉, 컨테이너는 하나의 표준이고, 도커는 이를 구현하는 도구 중 가장 메이저한 한 가지 선택지일 뿐이다.
컨테이너를 쓰면 뭐가 좋을까?
컨테이너 자체로도 코드를 실행할 수 있는 모든 요건을 갖췄기 때문에, 동일한 컨테이너는 항상 동일한 환경을 제공할 수 있다. 이는 2가지의 이점을 제공한다.
- 이식성 - 여러 머신에서 동일 프로그램을 구동하고자 하는 경우,(ex: Scale-out된 애플리케이션 서버) 필요한 여러 종속성을 일일이 설치하는 귀찮음을 감수할 필요가 없어진다.
- 독립성 - 동일 머신에서 서로 버전이 다른 동일 프로그램에 대한 종속성을 갖는다고 치자.(ex: mysql 버전이 5인 프로젝트와 mysql 버전이 8인 프로젝트) 이때 DB를 로컬 머신에 설치해 연결하고자 한다면, 매번 mysql 버전을 바꿔가며 프로젝트 개발을 해야 하고, 이는 생산성 저하를 가져올 수 있다. 도커를 사용해 실행 환경을 완전히 격리한다면, 이러한 불편함을 감수할 필요가 없어진다.
가상머신과 도커의 차이
도커에 대한 위의 설명을 읽어보면, 가상 머신(Virtual Machine)과 유사한 원리라고 생각할 수 있다.
확실히 가상머신과 도커 모두 물리적으로는 동일 머신에 있음에도 논리적으로 실행 환경을 분리하고자 할 때 사용한다. 그러나 둘 중에서는 도커가 훨씬 가볍고 유연하다. 그 이유가 무엇일까?
가상 머신
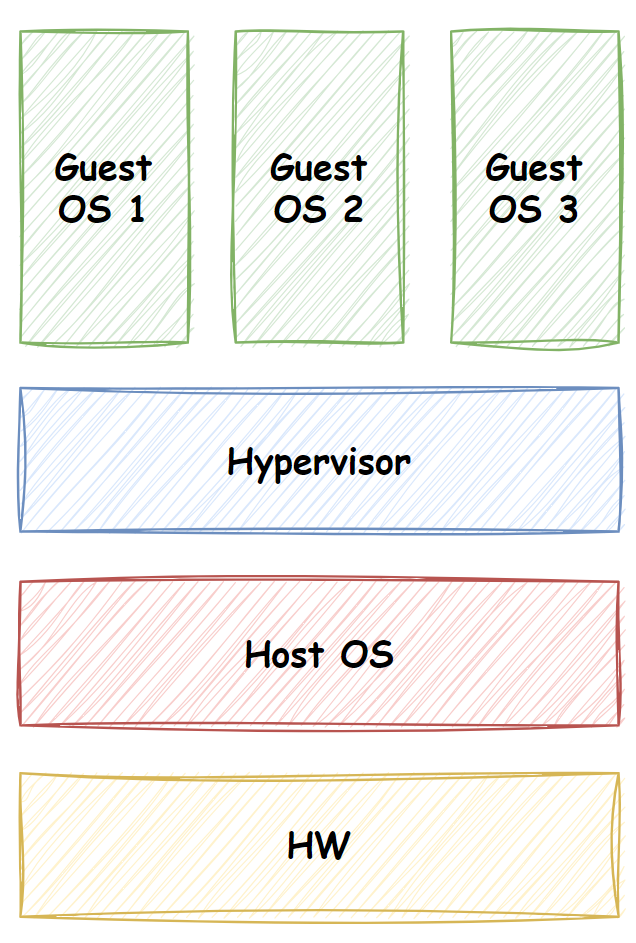
가상 머신은 하이퍼바이저를 통해 별도의 가상 운영체제를 설치해 동작한다. 가상 머신을 이용하는 경우 이 가상의 운영체제 자체의 구동을 위한 종속성과 도구들이 필요해진다.
즉, Host OS가 Windows인 머신에서 Linux 기반 프로그램을 구동하기 위해 Linux 가상 머신을 설치하는 것은, Linux 운영체제를 얻느라 더 많은 메모리/CPU/HDD 공간을 낭비하게 만든다.
도커
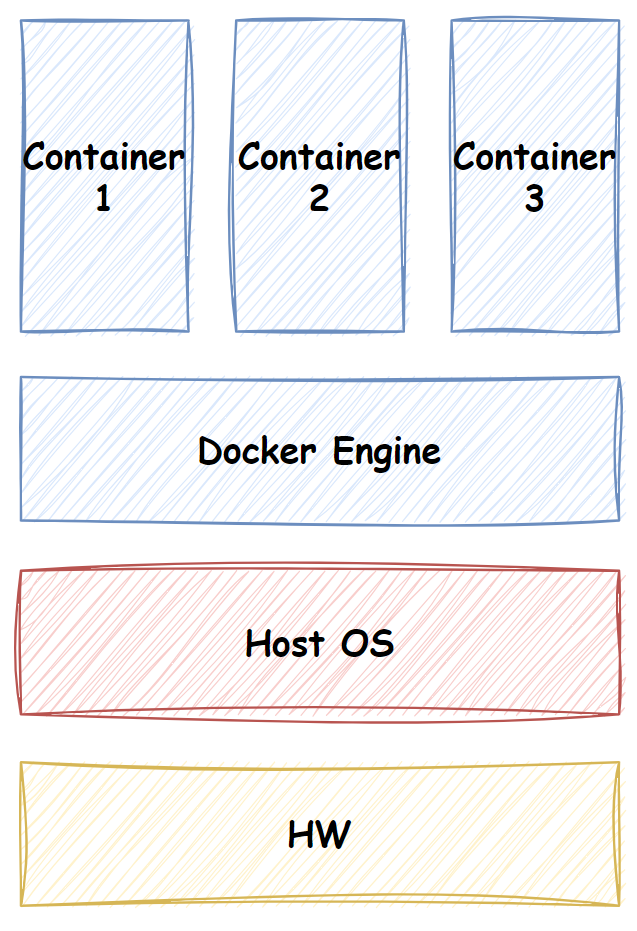
도커는 호스트 OS에 빌트인되어있는 내장 컨테이너 위에서 도커 엔진(docker engine)이라는 프로그램을 실행함으로써 동작한다. 도커는 OS 자체를 설치하지 않고도 특정한 격리된 실행 환경을 구축하도록 돕는다. 이는 가상 머신처럼 OS 자체의 설치를 위해 불필요한 자원을 낭비하지 않도록 한다.
이미지와 컨테이너
도커는 이미지를 기반으로 컨테이너를 생성해 실행한다.
이미지란, 컨테이너 생성을 위한 설정 및 코드를 포함한 템플릿이자 스냅샷이다. 어떤 기반 이미지를 사용할지, 컨테이너에 어떤 데이터를 포함시키고, 어떤 포트를 노출하고, 어떤 환경 변수를 주입할지 등의 정보를 이미지 생성 단계에서 결정한다.
이미지는 이를 생성하기 위한 파일(Dockerfile)로부터 빌드(생성)되고, 우리는 이 빌드된 이미지를 기반으로 컨테이너를 생성해 실행하게 된다.
즉, 이미지와 컨테이너의 관계는 Java의 클래스와 인스턴스의 관계와 유사하다고 볼 수 있다. 이미지라는 설계도를 기반으로 다수 개의 실행 주체인 컨테이너를 생성할 수 있게 되는 것이다.
이미지와 컨테이너의 계층 구조
도커의 이미지와 컨테이너는 모두 계층 구조로 이루어진다. 이미지를 만들기 위한 명령들이 순서대로 하나씩 레이어(layer)로 쌓이며, 컨테이너가 생성된 후 실행되는 명령들도 그 위에 레이어로 쌓이게 된다.
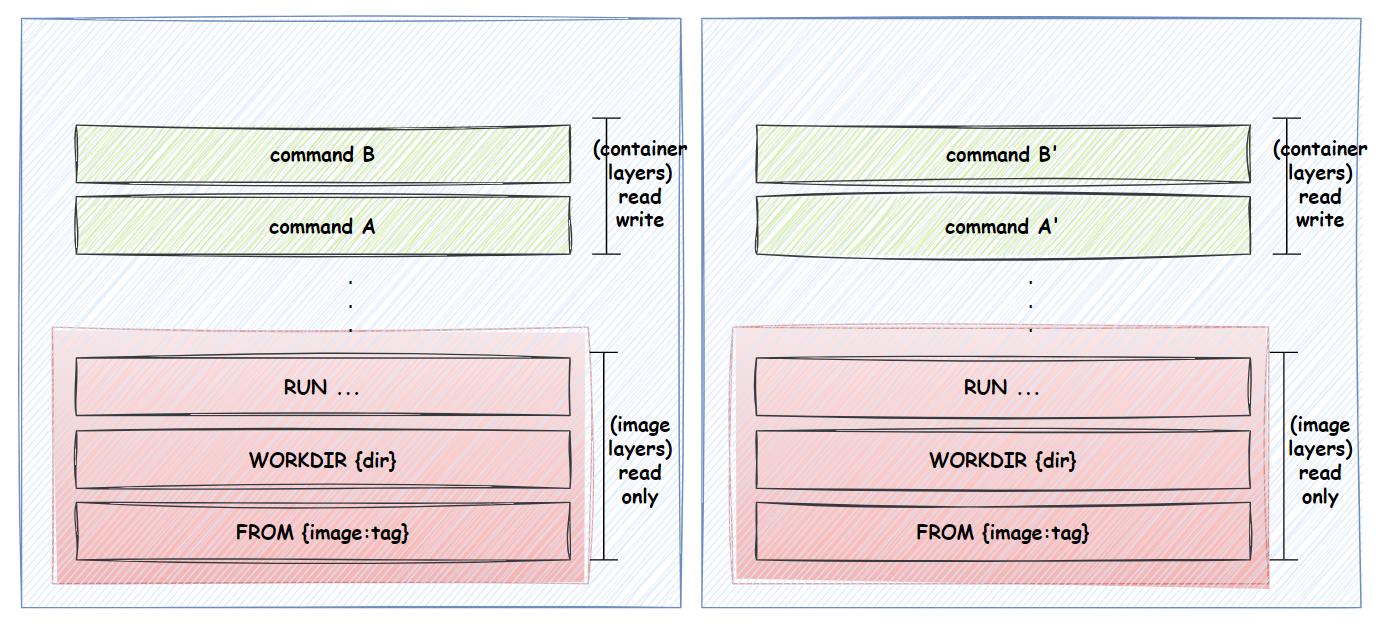
이러한 계층 구조에서 유의할 점은 2가지이다.
- 계층 구조를 기반으로 캐싱되고 재구축된다.
여기서FROM {image:tag} WORKDIR {dir} RUN commandWORKDIR라인을 변경하게 되면, 해당 라인부터 캐싱된 데이터를 invalidate 처리하고 다시 명령을 수행하게 된다. - 이러한 레이어 기반의 캐싱 방식에 주의하여 명령들의 위치를 잘 조정하는 것도 캐시를 효율적으로 사용하기 위한 중요한 체크포인트이다. 앞 단계에 자주 변경되는 명령이 위치하면 그 이후 단계에 생성되는 레이어들이 불필요하게 재생성되는 일이 생길 수도 있기 때문이다.
- 위의 레이어 중 이미지 빌드 중 생성된 레이어는 아래와 같은 명령들을 통해 생성된다.
- 이미지는 read-only, 컨테이너는 read-write 레이어이다.컨테이너는 생성 후에도 내부의 데이터를 수정할 수 있다. 컨테이너 계층에는 새 명령들이 수행되며 변경 사항이 생길 때마다 새 레이어가 계속 쌓여 나가게 된다.
- 이미지는 한 번 만들어지고나면 수정이 불가능하다. 변경이 필요하다면 새 이미지를 빌드해 사용해야 한다.
도커에 대해 더 자세히 알아보기
이외에도 도커는 더 다양한 도구들을 제공한다.
도커의 스토리지 시스템인 볼륨(volume)은 도커가 가상머신과 달리 호스트와 유연하게 데이터를 공유할 수 있는 강력한 도구이다.
또한, 도커는 별도의 네트워크를 구축해 컨테이너 간 통신을 용이하게 만들 수 있다. 즉, OS 레벨에서의 분리가 아니기 때문에 호스트-컨테이너 간, 컨테이너와 컨테이너 간 데이터나 정보를 주고받는 일이 더 자유롭게 일어난다.
이와 관련하여 더 자세한 내용을 알고 싶다면 아래 강의를 추천한다. 특히 도커를 통해 컨테이너 기반으로 다수 개 시스템이 구축되어 활발하게 통신하는 서비스를 구축하고자 하는 모든 사람들에게 이 강의를 추천한다.
【한글자막】 Docker & Kubernetes : 실전 가이드