

Long-Running 작업이란?
Long-Running 작업이란, 클라이언트에게 리소스를 제공하기 위해 아주 긴 시간을 요구하는 작업을 말합니다.
고비용 연산을 요구하는 AI 기반 서비스들이 늘어나는 최근에는 이러한 Long-Running 작업의 사례를 주변에서 쉽게 찾아볼 수 있죠. 대표적인 사례로, chat GPT의 이미지 생성 기능인 'Dall-E'가 있습니다.

이러한 Long-Running 작업을 사용자에게 제공하기 위해서는 많은 요소를 고려해야 하는데요. 오랜 시간을 요구하는 작업인 만큼 자칫하면 서버에 부하를 가져올 수 있고, 그로 인해 사용자가 서비스를 제공받기 위해 너무 오랜 시간을 기다리게 만들 수도 있기 때문입니다.
이번 글에서는 제가 Long-Running 작업을 포함한 API를 효율적으로 운영하기 위해 고려했던 점들에 대한 이야기를 나눠보고자 합니다.
Long-Running API를 운영하기 위한 고려
Polling
일반적으로, API는 리소스의 생성 요청을 받으면 응답으로 요청된 자원을 생성하여 반환하게 됩니다.
하지만, Long-Running 작업을 포함한 API에서는 리소스 생성 요청을 받은 서버가 작업을 완수한 후 그 결과를 담은 응답을 반환하게 된다면 아래와 같은 문제가 생길 수 있습니다.
- 스레드 부족 - 하나의 요청이 오랜 시간 스레드를 점유하게 되면서, 스레드 풀 내 유휴 스레드 수가 부족해질 수 있습니다.
- 즉각적인 인터렉션의 어려움 - 요청 시점부터 작업이 완료되고 리소스가 제공되는 순간까지 클라이언트와 서버 간에 어떠한 추가적 데이터 교환도 없게 되어, 사용자에게 실시간의 인터렉션을 제공하기 어렵습니다. 이는 사용자가 요청한 작업이 수행되고 있는지 알기 어렵게 만들어 사용성에 악영향을 줄 수도 있습니다.
이러한 상황에 적용할 수 있는 기법으로 polling 기법이 있는데요. polling 기법이란, 서로 데이터를 주고받는 두 장치 간에 주기적인 상태 검사를 통해 데이터를 동기화할 수 있도록 하는 기법입니다.
Long-Running API에 polling 기법을 적용하면, 단일 요청이 리소스의 상태 체크를 포함한 여러 개의 요청으로 분리됨에 따라 아래와 같은 HTTP 요청-응답 플로우가 구성됩니다.
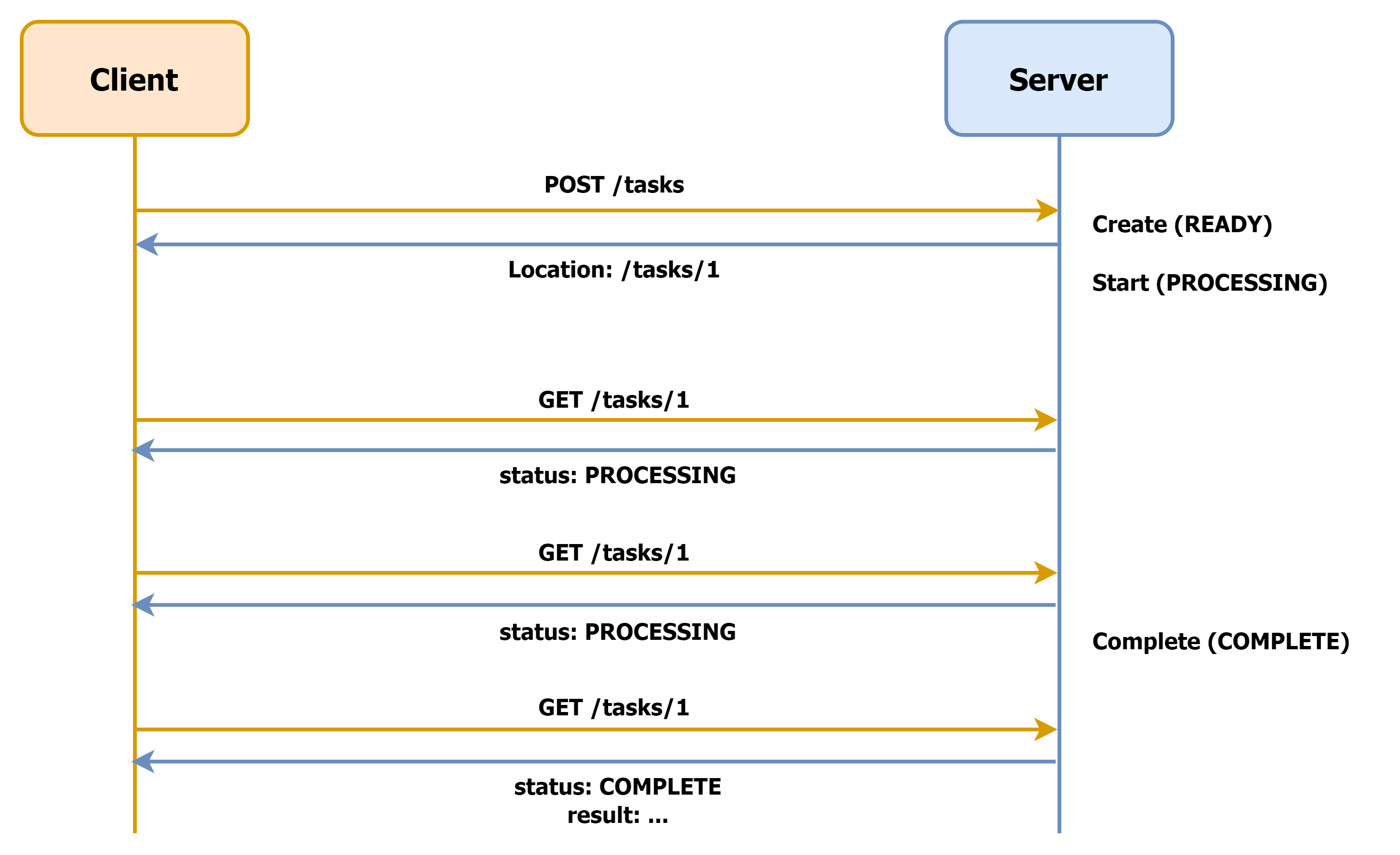
각 요청에 대한 세부적인 응답을 살펴보자면 아래와 같습니다. (편의상 HTTP 버전은 생략하였습니다.)
202 Accepted
Location: /tasks/1
{
"status": "READY",
"result": null,
"percentage": 0
}먼저 클라이언트가 작업의 생성 요청을 보내면, 요청한 리소스의 생성 작업이 접수되었음을 의미하는 202 상태 코드와 함께 리소스의 위치가 Location 헤더로 제공됩니다.
클라이언트는 이 응답을 받으면 Location 헤더의 리소스에 대한 polling을 시작하며, 작업이 완료되어 리소스가 이용 가능한 상태가 되면 아래와 같은 응답이 제공됩니다.
200 OK
{
"status": "COMPLETE",
"result": { ... },
"percentage": 100
}이제 클라이언트는 result 내 데이터를 꺼내 사용자에게 제공할 수 있습니다.
이러한 Polling 기법을 적용한다면, 위에서 언급했던 발생 가능한 문제들은 아래와 같이 개선됩니다.
- 스레드의 빠른 회수 - 서버는 작업을 접수한 후 바로 응답을 반환합니다. 하나의 요청이 오랜 시간 스레드를 점유하지 않습니다.
- 풍부한 인터렉션 제공 가능 - 서버는 API 호출자에게 거의 즉각적인 응답을 제공할 수 있습니다. 단순히 리소스를 생성하는 작업은 이를 검증하고 데이터베이스에 저장하는 등의 아주 간단한 로직만을 포함할 것이기 때문이죠. 또한, 서버는 처리 중인 작업에 대한 다양한 정보를 제공할 수 있게 됩니다. 진행 상태(status), 진척도(percentage) 등이 이에 해당합니다.
이러한 이유로 오랜 처리 시간을 포함한 API의 제공을 위해서는 polling 기법 또는 WebSocket 등의 기술을 적용하여 클라이언트가 서버의 처리 상황을 실시간으로 주고받을 수 있도록 하는 편이 좋습니다.
취소 탐지 (Cancel Detection)
Long-Running 작업은 긴 시간을 요구하는 작업입니다. 작업을 처리하는 동안 다양한 이유로 사용자가 이탈하게 될 수 있는데요. 만약 서버가 이미 떠난 사용자를 위한 작업을 열심히 처리하고 있다면, 서버는 불필요한 리소스 낭비를 하고 있는 셈이 되겠죠. 이러한 낭비를 방지하기 위해 서버는 사용자로부터 발생한 취소 동작을 탐지할 수 있어야 합니다.
취소 동작을 탐지하기 위해 사용할 수 있는 아주 단순하고 익숙한 방법이 있습니다. 바로, 작업 취소 API를 제공해 사용자가 작업 처리 대기를 중단했을 때 이를 호출할 수 있도록 하는 것입니다.
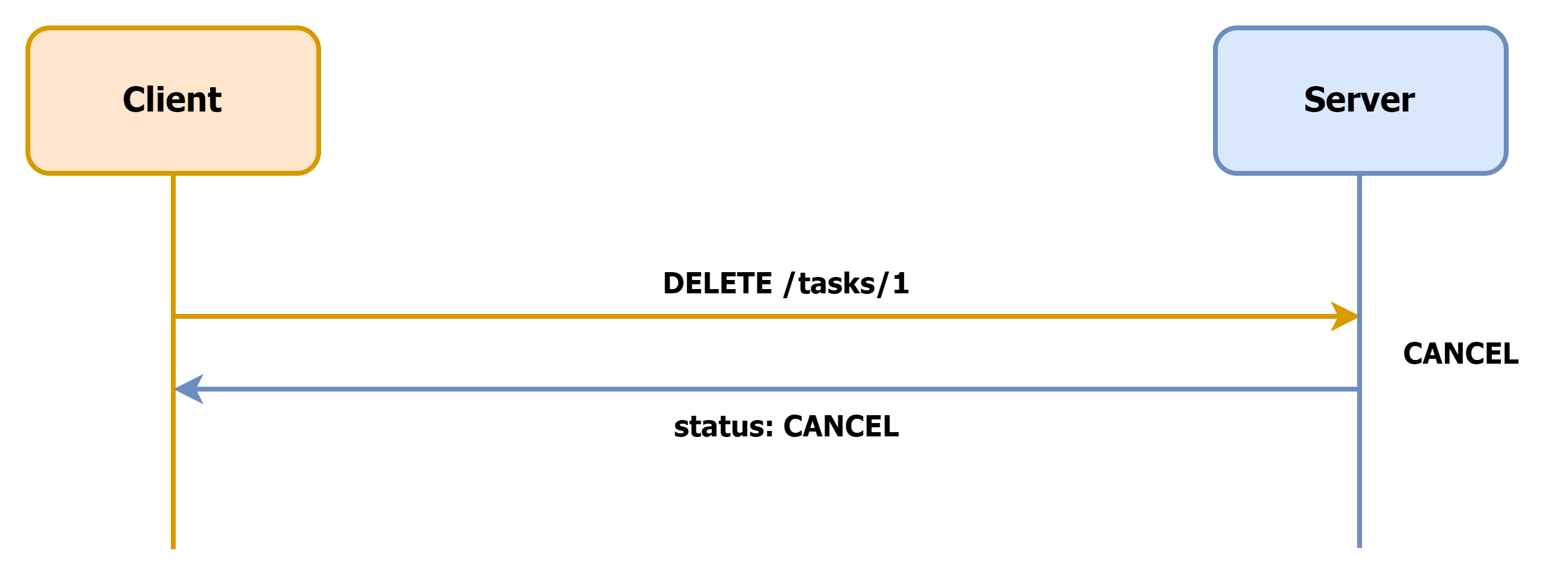
200 OK
{
"status": "CANCEL",
"result": null
}취소 API를 제공할 때는 아래와 같은 요소를 고려하는 것이 좋습니다.
- 리소스를 실제로 제거하는 대신 취소를 기록하기 - 실제로 처리될 작업이 아니라고 해도, 이러한 취소 동작을 기록하는 것은 추후 소중한 통계 자료가 되기도 합니다. “요청 후 N초 후부터 사용자의 이탈이 많았다” 등의 기록은 추후 서비스를 개선할 방향을 때에도 많은 도움을 주기 때문이죠. 이러한 이유로, 취소 API는 리소스를 실제로 제거하는 방향보다는 “취소 동작의 발생 시점과 함께 리소스의 처리가 사용자에 의해 취소됐음”을 기록하도록 구현하는 편이 좋습니다.
- 취소 작업도 Long-Running 작업인지 확인하기 - 경우에 따라 진행 중이던 작업을 취소하는 것 또한 오랜 시간을 요구하는 작업이 될 수도 있습니다. 이럴 때에는 취소 처리 후 응답을 제공하기보다는 취소 처리와 응답을 다시 비동기로 분리하는 편이 좋습니다.
사용자의 취소 동작을 서버가 인지할 수 있도록 취소 API를 제공하는 것도 Long-Running API의 운영에 많은 도움을 줍니다. API 제공 등을 통해 간단하게 달성될 수 있는 경우, 취소를 탐지하고 기록할 수 있도록 하는 것이 좋습니다.
과다 요청 사용자 제어를 위한 Rate Limit 설정
한 명의 사용자로부터 너무 많은 요청이 발생했을 때, 서버가 이 요청을 모두 받아 처리하려 한다면 서버의 자원이 부족해져 다른 사용자들이 이용에 불편함을 겪을 수 있겠죠.
이를 예방하기 위해 Long-Running API에는 Rate Limit(처리율 제한)을 두는 것이 좋은데요. 최대 2회의 초당 요청을 허용하는 API로 간단한 예시를 들자면, 아래와 같은 요청-응답 플로우가 구성됩니다.
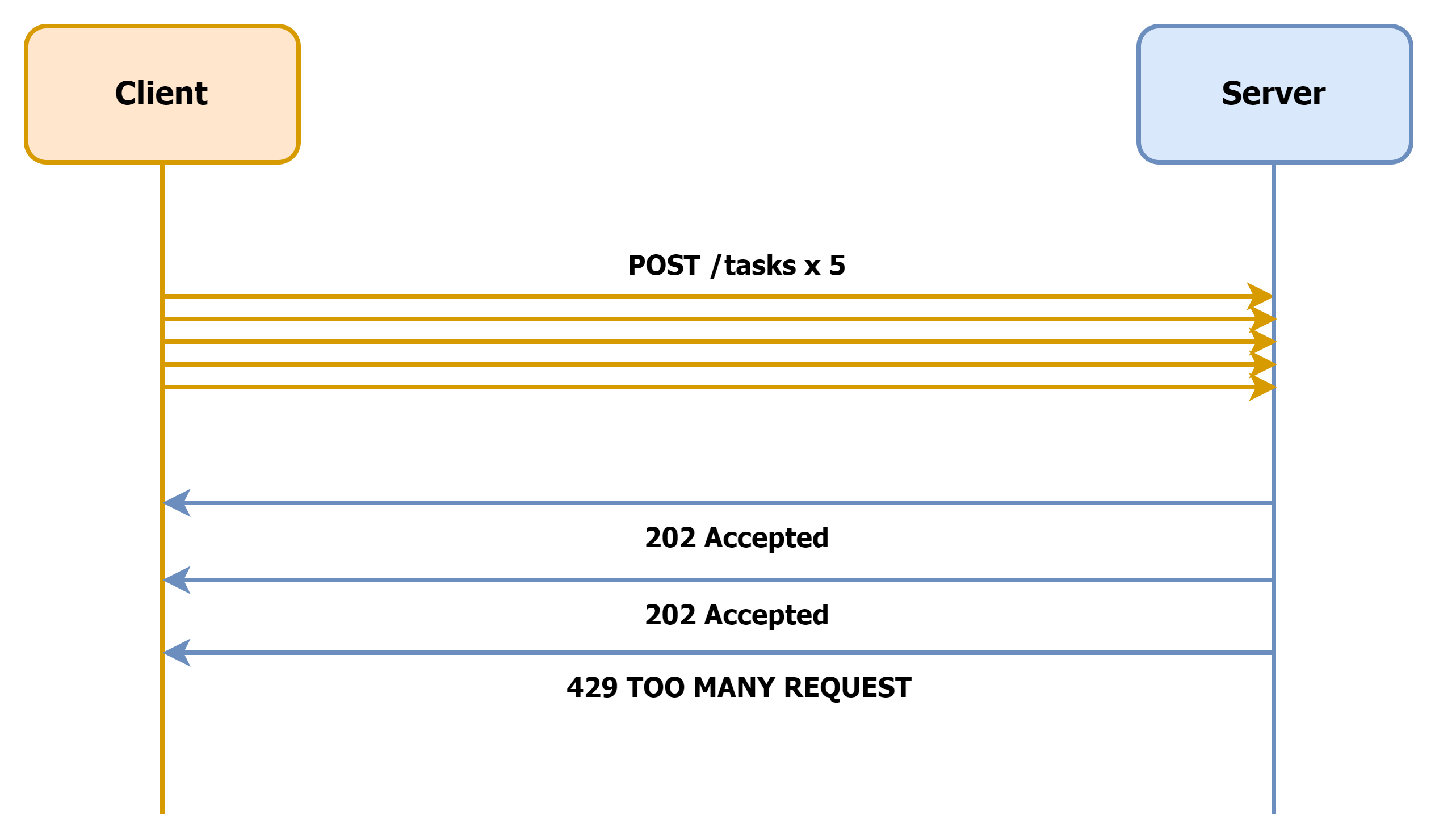
Rate Limit을 적용하는 경우, 서버는 HTTP Status Code 429 (TOO MANY REQUEST)를 반환하여 과다 요청에 의해 서버가 요청 처리를 거부했음을 명시적으로 드러내는 것이 좋습니다.
이러한 기능은 사용자별 요청 횟수를 기록하고 이 데이터에 만료 시간을 설정할 수 있는 저장 공간을 활용함으로써 구현할 수 있습니다. 현재 저희는 Redis에 이 데이터를 저장하고 expire를 설정함으로써 이 기능을 운영하고 있습니다.