

실습 환경은 Python 3.6과 tensorflow 1.5이다.
오토인코더(AutoEncoder)
정답이 주어지지 않고, 비슷한 데이터끼리 묶는 군집화에 주로 사용되는 비지도학습의 대표적인 신경망.
은닉층의 노드 수가 입/출력 계층의 노드 수보다 적다는 특징을 가진다. 그 이유는, 오토인코더가 데이터를 압축하거나 노이즈를 제거하는 데에 주로 사용되기 때문이다.
오토인코더로는 변이형 오토인코더(VA), 후자를 잡음제거 오토인코더(DA) 등 다양한 방식이 존재한다.
오토인코더 구현
역시 이번에도 MNIST 데이터셋을 이용한다.
MNIST에 대해 잘 모른다면, 이전 포스팅을 참고하라.
2020/07/19 - [개발 일지/ML] - MNIST 학습 모델 만들기
MNIST 학습 모델 만들기
실습 환경은 Python 3.6과 tensorflow 1.5이다. MNIST 손으로 쓴 숫자 이미지를 모아 둔 데이터셋. 데이터가 잘 정제되어 있어, 학습자들에게 머신러닝 학습의 기초로 쓰인다. 1. 데이터셋 읽어 오기 import
devpanpan.tistory.com
1. 하이퍼파라미터 설정
learning_rate = 0.01 # 학습률
training_epoch = 20 # 총 학습 횟수
batch_size = 100 # 미니배치 한 번에 학습할 데이터 개수
n_hidden = 256 # 은닉층의 뉴런 개수
n_input = 28 * 28 # 입력값의 크기 (784)구현에 쓰일 변수들의 값은 다음과 같이 설정하였다.
주의할 점은 앞서 말했듯 n_hidden(은닉층)의 뉴런 개수가 n_input(입력층)의 뉴런 개수보다 적어야 한다는 것이다.
(은닉층이 더 큰 오토인코더 모델도 존재하기는 한다)
2. 인코더와 디코더 생성
X = tf.placeholder(tf.float32, [None, n_input])우선 플레이스 홀더를 설정한다.
# 입력층 -> 은닉층: 인코더(encoder)
# 인코더의 가중치와 편향
W_encoder = tf.Variable(tf.random_normal([n_input, n_hidden]))
b_encoder = tf.Variable(tf.random_normal([n_hidden]))
# 인코더
encoder = tf.nn.sigmoid(tf.add(tf.matmul(X, W_encoder), b_encoder))
# 은닉층 -> 출력층: 디코더(decoder)
# 디코더의 가중치와 편향
W_decoder = tf.Variable(tf.random_normal([n_hidden, n_input]))
b_decoder = tf.Variable(tf.random_normal([n_input]))
# 디코더
decoder = tf.nn.sigmoid(tf.add(tf.matmul(encoder, W_decoder), b_decoder))인코더는 입력층으로 들어온 데이터를 은닉층으로 내보내는 작업을,
디코더는 은닉층으로 들어온 데이터를 출력층으로 내보내는 작업을 한다.
이 일련의 과정을 수행하는 이유는
출력값이 입력값과 비슷해지도록 인코더와 디코더의 가중치와 편향을 설정하기 위해서라는 점에 주목하자.
(같은 이유로, 출력층과 입력층은 같은 개수의 뉴런을 갖는다.)
3. 손실, 최적화 함수 구성
# 손실
# 실제 입력값(X)과 예측값인 decoder가 반환하는 값(decoder) 사이의 거리 함수로 구현
cost = tf.reduce_mean(tf.pow(X- decoder, 2))
# 최적화
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)손실과 최적화 함수는 다음과 같이 구성하였다.
4. 학습
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs})
total_cost += cost_val
print('Epoch:', '%04d '%(epoch+1),
'Avg. cost =', '%.4f'%(total_cost/total_batch))학습 횟수는 하이퍼파라미터에서 설정해주었듯 20회이다.
5. 결과 확인
# matplotlib을 통한 결과 확인
sample_size = 10
samples = sess.run(decoder, feed_dict={X: mnist.test.images[:sample_size]})
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
# 출력
# 위(ax[0][i]): 입력값 이미지
# 아래(ax[1][i]): 신경망이 생성한 이미지
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.show()matplotlib을 통해 이미지를 출력함으로써 결과를 가시적으로 확인하였다.
결과 화면은 아래와 같았다.
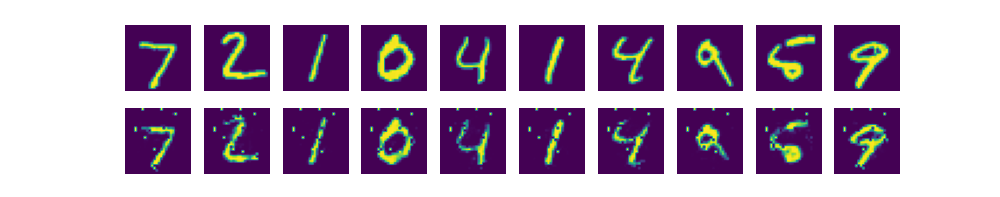
신!기!
이 오토인코더를 응용하면 초상화 그리기와 같은 모델을 구현할 수 있겠구나 하는 생각이 들었다.