

실습 환경은 Python 3.6과 tensorflow 1.5이다.
GAN
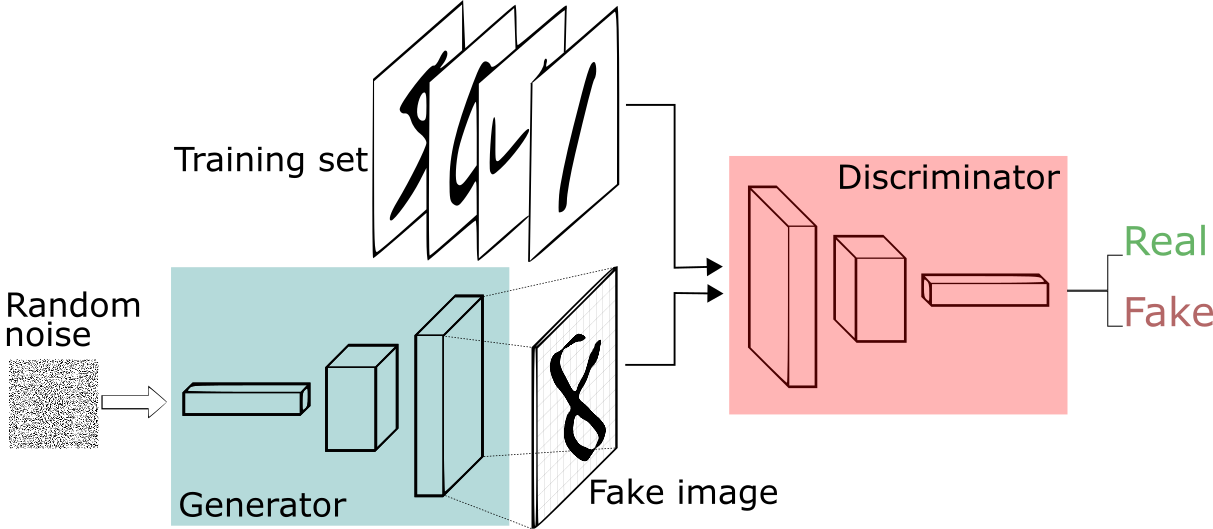
(이미지 출처: Thalles Silva)
생성자(Generator)와 구분자(Discriminator)를 설정하여 대립적으로 작용하게 함으로써,
생성자가 더욱 진짜에 가까운 데이터(Noise -> Fake image)를 생성해내도록 하는 비지도학습 모델.
GAN에 대한 예시를 들 때 빠지지 않는 설명이 이안 굿펠로우의 논문에 제시된 비유이다.
이 비유에서는, 생성자를 위조지폐를 생성하는 위조지폐범, 구분자를 경찰로 설정한다. 경찰이 위조지폐를 최대한 감별하려고 노력할수록, 위조지폐범 역시 더욱 정교한 위조지폐를 만들어내게 된다.
개인적인 생각으로는 보안 관리자와 해커 사이의 상호작용과도 닮은 것 같다. 보안 기술이 발전하고 암호화 기법이 정교해질수록 해커들 또한 발전된 해킹 기술을 갖추기 때문이다.
GAN 구현하기
이번에도 지금까지와 동일하게 MNIST 데이터셋을 이용한다.
MNIST에 대해 잘 모른다면 다음 포스팅을 참고하라.
2020/07/19 - [개발 일지/ML] - MNIST 학습 모델 만들기
MNIST 학습 모델 만들기
실습 환경은 Python 3.6과 tensorflow 1.5이다. MNIST 손으로 쓴 숫자 이미지를 모아 둔 데이터셋. 데이터가 잘 정제되어 있어, 학습자들에게 머신러닝 학습의 기초로 쓰인다. 1. 데이터셋 읽어 오기 import
devpanpan.tistory.com
1. 하이퍼파라미터 설정
total_epoch = 100 # 총 학습 횟수
batch_size = 100 # 미니배치 한 번에 학습할 데이터 개수
learning_rate = 0.0002 # 학습률
n_hidden = 256 # 은닉층의 뉴런 개수
n_input = 28 * 28 # 입력값의 크기 (784)
n_noise = 128 # 생성자의 입력값인 노이즈의 크기하이퍼파라미터는 다음과 같이 설정하였다.
2. 생성자, 구분자 신경망 구축
X = tf.placeholder(tf.float32, [None, n_input])
Z = tf.placeholder(tf.float32, [None, n_noise])플레이스홀더를 설정한다.
X는 입력값으로 주어지며, Z는 노이즈 입력값으로 주어진다.
신경망은 함수 형태로 구축한다. 그전에, 신경망에 사용될 변수를 먼저 설정한다.
# 생성자 신경망 변수
# 노이즈(입력층) -> 은닉층
G_W1 = tf.Variable(tf.random_normal([n_noise, n_hidden], stddev=0.01))
G_b1 = tf.Variable(tf.zeros([n_hidden]))
# 은닉층 -> 구분자의 입력층
G_W2 = tf.Variable(tf.random_normal([n_hidden, n_input], stddev=0.01))
G_b2 = tf.Variable(tf.zeros([n_input]))
# 구분자 신경망 변수
# 입력층 -> 은닉층
D_W1 = tf.Variable(tf.random_normal([n_input, n_hidden], stddev=0.01))
D_b1 = tf.Variable(tf.zeros([n_hidden]))
# 은닉층 -> 출력층(0~1 사이의 수)
D_W2 = tf.Variable(tf.random_normal([n_hidden, 1], stddev=0.01))
D_b2 = tf.Variable(tf.zeros([1]))구분자는 결과값으로 0~1 사이의 값을 출력한다.
구분자의 역할은 실제 데이터와 생성자가 만든 데이터가 서로 얼마나 비슷한지 판단하는 것이기 때문이다.
이제 신경망을 구축하자.
# 생성자 신경망
# 파라미터로 무작위로 생성한 노이즈를 받아 구분자의 입력 데이터
def generator(noise_z):
hidden = tf.add(tf.matmul(noise_z, G_W1), G_b1)
hidden = tf.nn.relu(hidden)
output = tf.add(tf.matmul(hidden, G_W2), G_b2)
output = tf.nn.sigmoid(output)
return output
# 구분자 신경망
# 입력을 받아 0~1 사이의 값을 출력
def discriminator(inputs):
hidden = tf.add(tf.matmul(inputs, D_W1), D_b1)
hidden = tf.nn.relu(hidden)
output = tf.add(tf.matmul(hidden, D_W2), D_b2)
output = tf.nn.sigmoid(output)
return output
마지막으로, 신경망을 통해 생성자와 구분자를 만들어 낸다.
# fake image를 만들 G
G = generator(Z)
# fake image를 받을 D_gene
D_gene = discriminator(G)
# real image를 받을 D_real
D_real = discriminator(X)이제 이들의 학습을 통해, 생성자가 더 진짜 같은 데이터를 만들어내도록 할 수 있다.
3. 손실과 최적화 함수 설정
손실은 다음과 같다.
# 손실1: 경찰 학습용, D_real(실제) + 1-D_gene(가짜) 값을 최대화
loss_D = tf.reduce_mean(tf.log(D_real) + tf.log(1- D_gene))
# 손실2: 위조지폐범 학습용, D_gene(가짜) 값을 최대화
loss_G = tf.reduce_mean(tf.log(D_gene))생성자를 위한 손실과 구분자를 위한 손실은 따로 만들어줘야 한다. 두 신경망이 목표로 하는 것이 정 반대이니 당연한 것이기도 하다.
구분자는 실제와 점점 가깝게, 생성자는 가짜와 점점 가깝게 손실값이 변화해야 한다.
최적화 함수를 설정할 때에도 구분자와 생성자는 명확히 구분되어야 한다.
서로의 학습에 영향을 미치면 안되기 때문이다.
따라서 이 명확한 구분을 위해 두 신경망의 관련 변수를 분리, 리스트화하여 전달한다.
D_var_list = [D_W1, D_b1, D_W2, D_b2]
G_var_list = [G_W1, G_b1, G_W2, G_b2]이를 고려한 최적화 함수는 다음과 같다.
# 최적화
train_D = tf.train.AdamOptimizer(learning_rate).minimize(-loss_D, var_list=D_var_list)
train_G = tf.train.AdamOptimizer(learning_rate).minimize(-loss_G, var_list=G_var_list)
4. 학습
학습은 지금까지와 큰 차이가 없다. 다만 한번에 두 개의 신경망을 학습할 뿐이다. (따라서 변수 분리가 중요하다)
# 학습
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 미니배치
total_batch = int(mnist.train.num_examples / batch_size)
# 두 손실의 결과값을 담을 변수
loss_val_D, loss_val_G = 0, 0
for epoch in range(total_epoch):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
noise = getNoise(batch_size, n_noise)
_, loss_val_D = sess.run([train_D, loss_D], feed_dict={X: batch_xs, Z: noise})
_, loss_val_G = sess.run([train_G, loss_G], feed_dict={Z: noise})
print('Epoch:', '%04d'%epoch,
'D loss:', '%.4f'%loss_val_D,
'G loss:', '%.4f'%loss_val_G)구분자의 학습에는 노이즈가 입력값이 되어 입력층에 전달되고, 0과 1 사이의 값이 출력되는 모든 과정이 포함되므로 플레이스홀더 X와 Z에 대한 값이 모두 전달된다.
생성자의 학습에는 노이즈가 입력되어 가짜 데이터를 출력하는 과정만이 포함되므로 플레이스홀더 Z(noise)에 대한 값만이 전달된다.
5. 결과 확인
결과 확인을 위한 코드는 다음과 같다. 0, 9, 19, ... , 99 번째의 결과를 확인하고자 하였다.
# 10번에 한 번 꼴로 확인
if epoch == 0 or (epoch+1)%10 == 0:
sample_size = 10
noise = getNoise(sample_size, n_noise)
samples = sess.run(G, feed_dict={Z: noise})
fig, ax = plt.subplots(1, sample_size, figsize=(sample_size, 1))
for i in range(sample_size):
ax[i].set_axis_off()
ax[i].imshow(np.reshape(samples[i], (28, 28)))
plt.savefig('samples/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
결과는 다음과 같다.











아직 확실히 식별할 수 있는 정도는 아니지만, 학습을 반복하면서 숫자의 형태를 갖췄음은 확인할 수 있다.
다음 포스팅에서는 어떤 숫자를 만들어내려고 했는지도 함께 확인하는 코드를 짜보도록 한다.